代码已上传至github仓库:https://github.com/itaiit/spring-ai-learn
向量数据库是一种专门类型的数据库,在人工智能应用中发挥着关键作用。
在向量数据库中,查询与传统关系型数据库有所不同。它们不是寻找精确匹配,而是执行相似性搜索。当给出一个向量作为查询时,向量数据库会返回与查询向量“相似”的向量。
向量数据库用于将您的数据与人工智能模型集成。使用它们的第一步是将您的数据加载到向量数据库中。然后,当要将用户查询发送给人工智能模型时,会先检索一组相似的文档。这些文档随后作为用户问题的上下文,并与用户的查询一起发送给人工智能模型。这种技术被称为检索增强生成(Retrieval Augmented Generation,RAG)。
要将数据插入向量数据库,需将其封装在一个 Document 对象内。Document 类封装了来自数据源(如 PDF 或 Word 文档)的内容,并包含以字符串形式表示的文本。它还包含以键值对形式呈现的元数据,包括诸如文件名等详细信息。
当插入向量数据库时,文本内容会通过嵌入模型转换为数值数组,即浮点数数组(float[]),这被称为向量嵌入(vector embeddings)。诸如 Word2Vec、GLoVE 和 BERT 等嵌入模型,或 OpenAI 的 text-embedding-ada-002,被用于将单词、句子或段落转换为这些向量嵌入。
向量数据库的作用是存储这些嵌入,并便于进行相似性搜索。它本身并不生成嵌入。要创建向量嵌入,应使用 EmbeddingModel。
接口中的 similaritySearch 方法允许检索与给定查询字符串相似的文档。这些方法可以通过以下参数进行微调:
k:一个整数,指定要返回的最相似文档的最大数量。这通常被称为“top K”搜索,或“K最近邻”(KNN)。threshold:一个介于 0 到 1 之间的双精度值,值越接近 1 表示相似度越高。默认情况下,例如,如果你设置了一个 0.75 的阈值,那么只有相似度高于此值的文档才会被返回。Filter.Expression:一个用于传递类似 SQL 中的“where”子句的流式 DSL(领域特定语言)表达式的类,但它仅适用于Document的元数据键值对。filterExpression:基于 ANTLR4 的外部 DSL,接受以字符串形式的过滤表达式。例如,对于国家、年份和是否激活等元数据键,你可以使用如下表达式:country == 'UK' && year >= 2020 && isActive == true。
Redis对于向量数据库的解释
数据往往是非结构化的,这意味着它没有被一个明确的模式所描述。非结构化数据的例子包括文本段落、图像、视频或音频。处理和搜索非结构化数据的一种方法是使用向量嵌入。
什么是向量?在机器学习和人工智能中,向量是代表数据的数字序列。它们是模型的输入和输出,以数值形式封装底层信息。向量将文本、图像、视频和音频等非结构化数据转换成机器学习模型可以处理的格式。
它们为什么重要?向量捕捉了数据中固有的复杂模式和语义含义,使它们成为各种应用的强大工具。它们使机器学习模型能够更有效地理解和操作非结构化数据。
增强传统搜索。传统的基于关键词或词汇的搜索依赖于单词或短语的精确匹配,这可能会受到限制。相比之下,向量搜索,或称为语义搜索,利用向量嵌入中捕获的丰富信息。通过将数据映射到向量空间,相似的项目会根据它们的含义被放置在彼此附近。这种方法允许更准确和有意义的搜索结果,因为它考虑了查询的上下文和语义内容,而不仅仅是使用的精确词汇。
向量数据库的一些实现
这是目前spring ai提供的对于向量数据库的支持(2025-04-29):
- Azure Vector Search – The Azure vector store.
- Apache Cassandra – The Apache Cassandra vector store.
- Chroma Vector Store – The Chroma vector store.
- Elasticsearch Vector Store – The Elasticsearch vector store.
- GemFire Vector Store – The GemFire vector store.
- MariaDB Vector Store – The MariaDB vector store.
- Milvus Vector Store – The Milvus vector store.
- MongoDB Atlas Vector Store – The MongoDB Atlas vector store.
- Neo4j Vector Store – The Neo4j vector store.
- OpenSearch Vector Store – The OpenSearch vector store.
- Oracle Vector Store – The Oracle Database vector store.
- PgVector Store – The PostgreSQL/PGVector vector store.
- Pinecone Vector Store – PineCone vector store.
- Qdrant Vector Store – Qdrant vector store.
- Redis Vector Store – The Redis vector store.
- SAP Hana Vector Store – The SAP HANA vector store.
- Typesense Vector Store – The Typesense vector store.
- Weaviate Vector Store – The Weaviate vector store.
- SimpleVectorStore – A simple implementation of persistent vector storage, good for educational purposes.
Redis作为向量数据库的使用
如果要使用redis作为向量数据库需要RediSearch模块。这里我们可以使用redis cloud,直接创建一个database已经足够用了,或者查看已经加载的模块有没有加载redisearch,运行redis-cli module list命令,如果加载的话会显示:
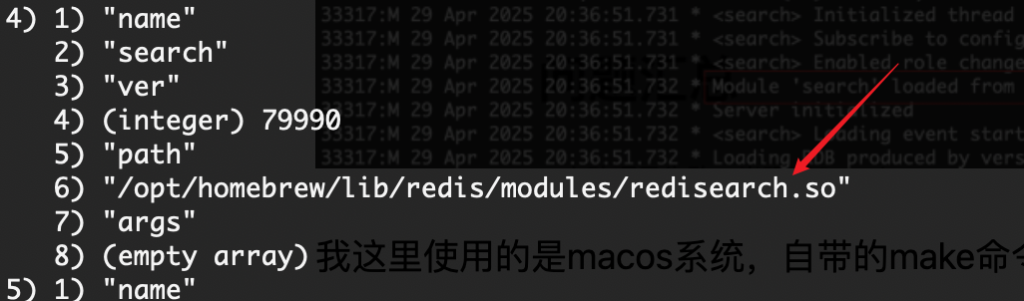
如果没有的话则需要编译RediSearch的源码。在编译完之后,根据编译文档的描述,使用make run命令即可直接加载RediSearch模块运行:

我这里使用的是macos系统,自带的make命令为3.81版本的,使用make命令的时候会显示版本太旧,在使用brew install make安装之后,默认不会连接到make执行命令而是gmake命令,因此在编译的时候时候使用gmake。运行的时候使用gmake run,或者修改redis.conf文件添加loadmodule命令进行加载。
使用redis cloud的方式,首先需要我们可以使用github关联来创建一个账号,然后我们可以免费使用一个30M大小的redis database。
在创建完成之后点击connect,在右侧会弹出多种方式连接该redis的代码示例,选择需要的方式即可:
根据上面对向量数据库的描述,当向向量数据库插入数据时,文本内容会通过嵌入模型转换为数值数组,即浮点数数组,然后保存到redis中。这里需要一个关键的模型叫做嵌入模型(embedding model)目前大多数的潜入模型在spring ai中都有预置的支持:

而对于现在流行的deepseek模型而言,由于其未发布对应的嵌入模型,因此在使用的时候嵌入模型只能选择已经支持的内置实现。除此之外,我们也可以自己定义一个对于新的嵌入模型的支持。经过对比,开源免费的嵌入模型可以选用BGE/M3E,支持中文并且可以本地部署,接下来我们会在本地运行一个BGE嵌入模型。
本地运行BGE嵌入模型
我这里使用python来运行bge模型,并对外暴露出端口来接收文本信息并输出对应的浮点数值数组。
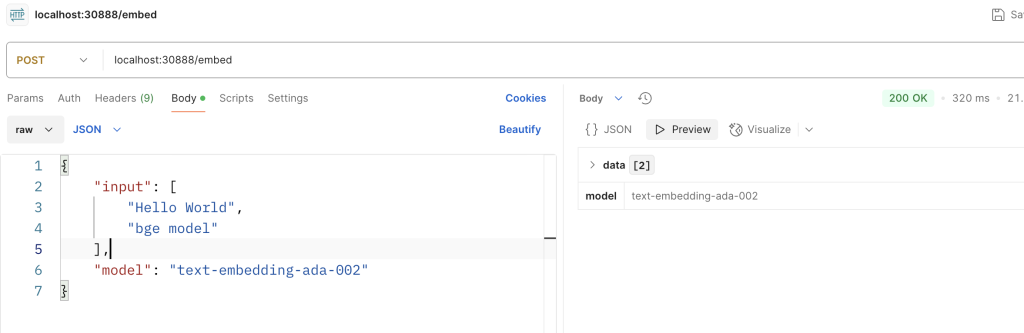
我这里设置的请求完整路径为:http://localhost:30888/embed。请求和输出响应结构为:
| 输入 | 输出 |
{ | { |
首先我们需要先下载模型到本地,可以在官网查看到bge系列的模型选择即可,我这里选用的是BAAI/bge-small-zh-v1.5。如果使用git clone一直失败的话,可以在仓库只下载model.safetensors即可,大小为90多兆。创建一个bge-small-zh-v1.5目录,并把文件放到目录中。
搭建python项目,我使用的python版本为3.12。安装python依赖:
pip install sentence-transformers flask torch uvicorn fastapi
编写python服务,创建 bge_service.py:
from fastapi import FastAPI
from sentence_transformers import SentenceTransformer
from pydantic import BaseModel
import uvicorn
app = FastAPI()
stdModel = SentenceTransformer("path/to/bge-small-zh-v1.5", device="cpu") # 根据硬件选择 "cuda"
class UserData(BaseModel):
input: list[str]
model: str
class GenEmbedding:
def __init__(self, index, embedding):
self.index = index
self.embedding = embedding
@app.post("/embed")
async def get_embedding(data: UserData):
embeddings = stdModel.encode(data.input, normalize_embeddings=True)
genEmbedding: list[GenEmbedding] = []
for index, value in enumerate(embeddings.tolist()):
genEmbedding.append(GenEmbedding(index, value))
return {"data": genEmbedding, "model": data.model} # 转成列表便于JSON序列化
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=30888)启动之后通过postman测试:
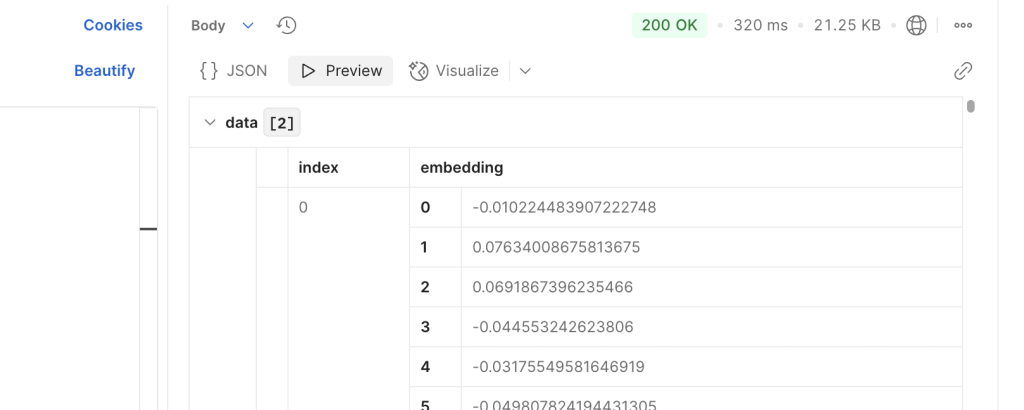
自定义EmbeddingModel实现,请求本地嵌入模型
1. 自动配置
我们在添加了spring-ai-starter-model-openai依赖之后,spring boot 默认会自动配置一个类型为OpenAiEmbeddingModel的bean:
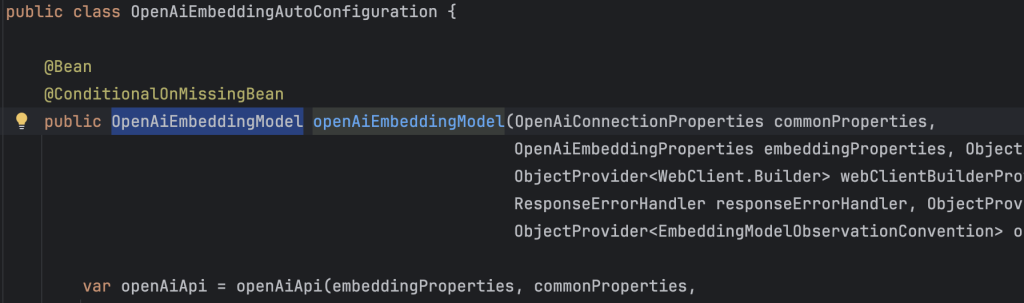
首先需要根据Condition条件进行排除,查看自动配置类上面的Condition可知生效的条件为:spring.ai.model.embedding未配置或者spring.ai.model.embedding=openai。于是我们这里将其自定义为bge。
2. 自定义EmbeddingModel实现
我们基于类org.springframework.ai.embedding.AbstractEmbeddingModel编写自己的实现类起名为BgeEmbeddingModel,并将其自动注入到Spring boot中。
在继承之后,会要求我们实现两个方法:
// 调用AI模型
@Override
EmbeddingResponse call(EmbeddingRequest request);
// 将输入文本转成向量
float[] embed(Document document);关于如何重写我们先看下面的调用图:
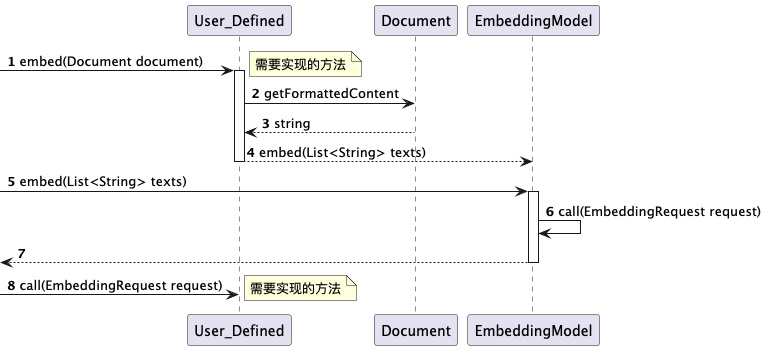
User_Defined是我们自定义的EmbeddingModel实现类,方法1,8是我们需要实现的方法。从上图中可以看到方法1在经过2-3步调用后,在第4步会同样调用到第5步的方法。方法5是接口EmbeddingModel中定义的默认实现方法:
default List<float[]> embed(List<String> texts) {
Assert.notNull(texts, "Texts must not be null");
return this.call(new EmbeddingRequest(texts, EmbeddingOptionsBuilder.builder().build()))
.getResults()
.stream()
.map(Embedding::getOutput)
.toList();
}在经过上面的分析之后,可以知道我们需要重点实现的是call方法。
3. call方法的实现
3.1. 获取输入的文本
方法的入参是EmbeddingRequest类型,通过getInstructions方法可以获取到我们要发向嵌入模型的文本。
3.2 包装成OpenAiApi.EmbeddingRequest请求参数
在OpenAiApi.EmbeddingRequest中规定的请求嵌入模型的标准参数格式,为了保持统一和方便我们也复用此格式。
3.3 向嵌入模型发送http请求,并包装响应数据
spring ai提供了OpenAiApi.EmbeddingList和OpenAiApi.Embedding的标准格式来接收嵌入模型的响应数据。完整格式的响应示例:
{
"object": "",
"data": [
{
"index": 0,
"embedding": [
-0.010224483907222748,
0.07634008675813675
],
"object": ""
}
],
"model": "bge-small-zh-v1.5",
"usage": ""
}3.4 将响应数据解析为EmbeddingResponse结构进行返回
更改application.yml文件
由于我们是自定义的嵌入模型并且是自定义的EmbeddingModel的实现,在配置文件中也有需要更改的地方要重点关注:
spring:
ai:
model:
embedding: bge
openai:
api-key: ${api-key}
base-url: https://api.deepseek.com
chat:
options:
temperature: 0.7
model: deepseek-chat
embedding:
base-url: http://localhost:30888
embeddings-path: /embed
vectorstore:
redis:
initialize-schema: true
index-name: custom-index
prefix: custom-prefix需要关注的地方:
- spring.ai.openai.embedding.base-url:需要填写我们的嵌入模型服务的地址
- spring.ai.openai.embedding.embeddings-path:嵌入模型服务接收文本并返回向量数据的请求uri
- spring.ai.model.embedding:自定义值
结果验证
1. 向redis向量数据库中写入数据
通过postman调用接口向redis vector database中写入数据:
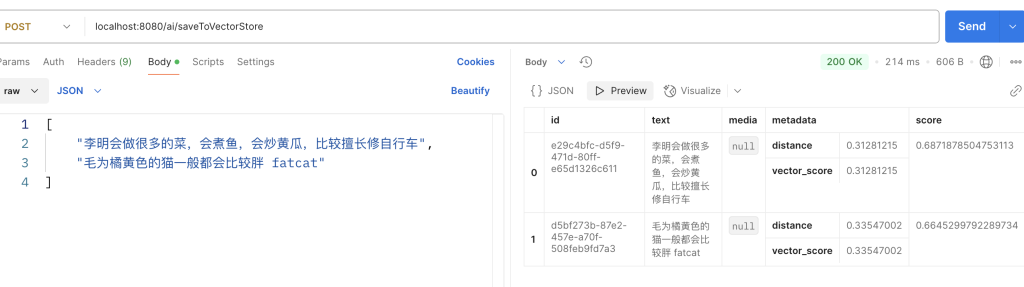
数据成功写入并且得到正确的返回结果。这里需要注意写入的单词需要使用空格隔开,否则在redis中查询相关词的时候会搜索不到。下面我们进入redis中进行查看:
1.1 FT._LIST命令查看索引

项目启动的时候会自动连接redis并创建索引。
1.2 FT.SEARCH查看索引下的数据
使用命令FT.SEARCH custom-index "fatcat"查看
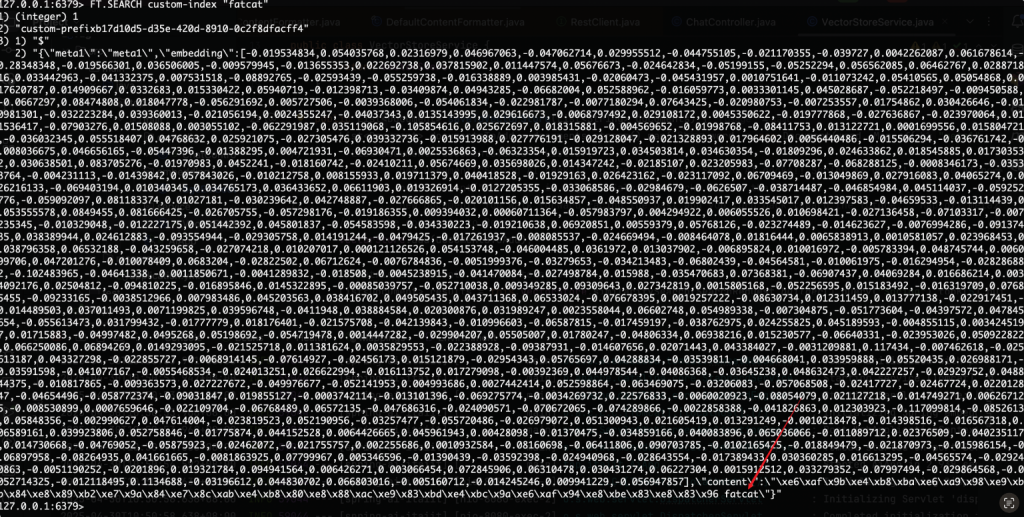
根据结果可以看到成功找到与这个条目有关的记录。
1.3 RAG验证,自动检索redis vector database补全
我们直接通过接口询问deepseek“李明的职业”:
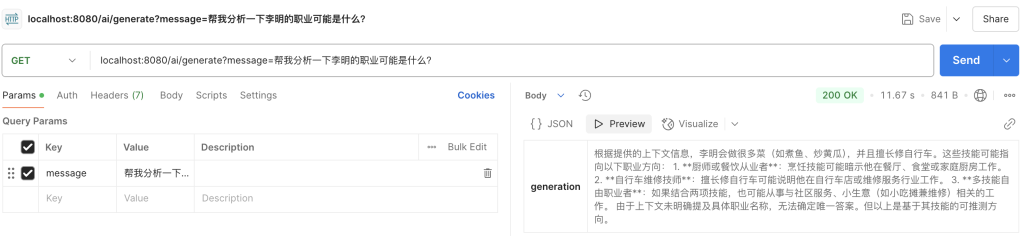
根据deepseek的回答,可以知道我们向deepseek提供的信息已经包括了之前存入redis中的李明的信息,llm并根据信息做出了推断。
问题汇总
1. 启动项目失败,出现ERR unknown command 'FT._LIST'错误

这个命令是redis的RediSearch模块的命令,可以使用命令redis-cli INFO modules查看该模块是否启用,查看输出的# Modules部分。redis的版本和RediSearch有依赖关系,可以查看redisearch。
最简单的方式:参考源码编译方式和依赖的安装教程:https://github.com/RediSearch/RediSearch/blob/master/developer.md
下载编译RediSearch,在执行make的时候可能会出现deps/readies/mk/main: No such file or directory的错误,这是因为在新版本中添加了子模块的依赖,需要执行git submodule init && git submodule update,issue1044。使用gmake编译boost1.84.0出现下面的错误
| error: a template argument list is expected after a name prefixed by the template keyword [-Wmissing-template-arg-list-after-template-kw] 82 | quat_traits::template write_element_idx(i, q) = s; | ^ |
修改源码删除掉template即可。https://github.com/boostorg/qvm/pull/55/files。